Phân tích cảm xúc trong Tiếng Việt

Trong bài viết này chúng ta sẽ tìm hiểu về cách phân tích cảm xúc trong Tiếng Việt, bao gồm các nội dung:
- Phân tích cảm xúc trong xử lý ngôn ngữ tự nhiên là gì?
- Ứng dụng của phân tích cảm xúc văn bản.
- Các phương pháp giải quyết bài toán phân tích cảm xúc.
- Sơ đồ huấn luyện mô hình phân tích cảm xúc văn bản Tiếng Việt (Sentiment Analysis Vietnamese - SAV).
- Một số lưu ý về điều chỉnh các siêu tham số của LSTMs.
- Thực hành tạo mô hình Sentiment Analysis Vietnamese (SAV).
- Phương pháp đánh giá mô hình Sentiment Analysis Vietnamese (SAV).
1. Phân tích cảm xúc trong xử lý ngôn ngữ tự nhiên là gì?
Phân tích cảm xúc (Sentiment analysis) là nhằm phát hiện ra thái độ mang tính lâu dài, màu sắc tình cảm, khuynh hướng niềm tin vào các đối tượng hay người nào đó.
Các vấn đề xung quanh việc phân tích cảm xúc:
- Nguồn gốc của cảm xúc.
- Mục tiêu của cảm xúc.
- Các loại cảm xúc: thích, yêu, ghét, đánh giá, mong mỏi...
- Về mức độ cảm xúc: tích cực, tiêu cực, trung tính.
- Văn bản hàm chứa cảm xúc: một câu hoặc một đoạn văn bản.
Bài toán phân tích cảm xúc thuộc dạng bài toán phân tích ngữ nghĩa văn bản. Vì vậy, ta cần phải xây dựng một mô hình để hiểu được ý nghĩa của câu văn, đoạn văn để quyết định xem câu văn đó hoặc đoạn văn đó mang màu sắc cảm xúc chủ đạo nào.
Phát biểu theo góc nhìn của máy học (Machine Learning) thì phân tích cảm xúc là bài toán phân lớp cảm xúc dựa trên văn bản ngôn ngữ tự nhiên. Đầu vào của bài toán là một câu hay một đoạn văn bản, còn đầu ra là các giá trị xác suất (điểm số) của N lớp cảm xúc mà ta cần xác định.
Trong loại bài toán phân tích cảm xúc được phân thành các bài toán có độ khó khác nhau như sau:
- Đơn giản: Phân tích cảm xúc (thái độ) trong văn bản thành 2 lớp: tích cực (positive) và tiêu cực (negative).
- Phức tạp hơn: Xếp hạng cảm xúc (thái độ) trong văn bản từ 1 đến 5.
- Khó: Phát hiện mục tiêu, nguồn gốc của cảm xúc (thái độ) hoặc các loại cảm xúc (thái độ) phức tạp.
Hiện tại thì cộng đồng khoa học mới chỉ giải quyết tốt bài toán phân tích cảm xúc ở cấp độ đơn giản, tức là phân tích cảm xúc với 2 lớp cảm xúc tiêu cực và tích cực với độ chính xác hơn 85%. Các cấp độ khó hơn chúng tôi cũng chưa biết có công trình nào giải quyết hay chưa. Nếu ai biết những công trình như vậy thì có thể giới thiệu cho chúng tôi.
Vì vậy, bài toán phân tích cảm xúc trong Tiếng Việt trình bày trong bài viết này là kết quả của nghiên cứu phân tích cảm xúc văn bản Tiếng Việt với 2 lớp cảm xúc là: tiêu cực (negative) và tích cực (positive). Sơ đồ phân tích cảm xúc như sau:
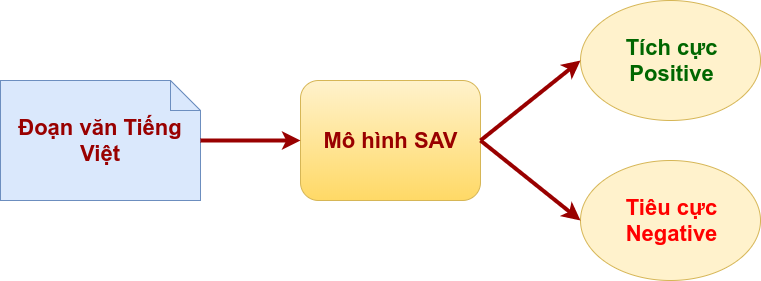
Đầu vào của mô hình xử lý Sentiment Analysis Vietnamese (SAV) là một đoạn văn Tiếng Việt, đầu ra là 2 giá trị xác suất mà đoạn văn đầu vào thuộc về lớp cảm xúc: tiêu cực (negative) hay tích cực (positive).
2. Ứng dụng của phân tích cảm xúc văn bản.
Việc phân tích cảm xúc trong văn bản được ứng dụng trong hàng loạt các vấn đề như: Quản trị thương hiệu doanh nghiệp, thương hiệu sản phẩm, quản trị quan hệ khách hàng, khảo sát ý kiến xã hội học, phân tích trạng thái tâm lý con người...
Chúng ta đang sống trong kỷ nguyên số, đặc biệt những năm gần đây nổi lên với mạng xã hội, với hàng triệu người dùng trên thế giới, với lượng thông tin nội dung được người dùng tạo ra hằng ngày cực kỳ lớn, với đa dạng các hình thức như dòng trạng thái, hình ảnh, video. Mạng xã hội có những đặc điểm là: thông tin do người dùng tạo ra, mang tính cá nhân cho nên chất lượng nội dung hay tính đúng đắn, xác thực là tương đối; một thông tin mới được tạo lại có sức lan tỏa nhanh đến đông đảo các người dùng khác, so với các kênh thông tin truyền thống như truyền hình, truyền thành, báo chí, diễn đàn, blog...
Điều này đặt ra cho các doanh nghiệp lớn giải quyết bài toán quản trị thương hiệu doanh nghiệp, quản trị thương hiệu sản phẩm trước các dư luận không tốt trên mạng xã hội rất khó khăn, cả về nguồn xuất phát thông tin, cả về khối lượng thông tin cần xử lý. Chưa kể việc các đối thủ cạnh tranh trên thương trường lợi dụng mạng xã hội để cố ý tạo các thông tin bất lợi cho nhau.
Một ví dụ cụ thể tại Việt Nam là vụ việc “con ruồi trong chai number one” của doanh nghiệp Tân Hiệp Phát gần đây, gây ảnh hưởng xấu đến hình ảnh của Tân Hiệp Phát và việc tiêu thụ sản phẩm nước uống tăng lực number one của doanh nghiệp này. Xét về luật pháp thì Tân Hiệp Phát là đúng nhưng không khéo léo trong việc xử lý quan hệ với khách hàng, gây bất bình trên mạng xã hội, đó lại là bài toán quản trị quan hệ với khách hàng mà doanh nghiệp phải giải quyết. Mà ai biết được các thông tin bất lợi về Tân Hiệp Phát này có được thúc đẩy bởi các đối thủ cạnh tranh hay không? Điều này đòi hỏi phải có một công cụ hỗ trợ đắc lực, mà chỉ có áp dụng công nghệ thông tin mới giải quyết được, chứ không lực lượng con người nào có thể làm xuể.
Rút kinh nghiệm từ Tân Hiệp Phát thì các doanh nghiệp lớn của Việt Nam hiện nay cũng đã đặt hàng các doanh nghiệp công nghệ thông tin giải quyết vấn đề này. Giải pháp công nghệ hiện nay được gọi là "lắng nghe mạng xã hội", tức là các doanh nghiệp CNTT mua các dữ liệu thời gian thực (real time) từ các công ty mạng xã hội về để xử lý các thông tin liên quan đến doanh nghiệp hay các sản phẩm mà doanh nghiệp đó kinh doanh, nhằm phát hiện và ngăn chặn sớm sự lan rộng các thông tin bất lợi trên mạng xã hội, có hình thức đính chính phản hồi đến các khách hàng của mình, đồng thời thương lượng, ngăn chặn tận gốc những người tạo ra các nội dung đó. Điều cốt yếu của giải pháp này chính là phân tích cảm xúc của các dòng trạng thái trên mạng xã hội nhằm lọc ra các thông tin bất lợi để xử lý.
3. Các phương pháp giải quyết bài toán phân tích cảm xúc.
Hiện nay, bài toán phân tích cảm xúc có 1 số phương pháp giải quyết như sau:
Phương pháp dựa trên từ điển các từ thể hiện cảm xúc. Theo đó, việc dự đoán cảm xúc dựa vào việc tìm kiếm các từ cảm xúc riêng lẻ, xác định điểm số cho các từ tích cực, xác định điểm số cho các từ tiêu cực và sau đó là tổng hợp các điểm số này lại theo một độ đo xác định để quyết định xem văn bản mau màu sắc cảm xúc gì. Phương pháp này có điểm hạn chế là thứ tự các từ bị bỏ qua và các thông tin quan trọng có thể bị mất. Độ chính xác của mô hình phụ thuộc vào độ tốt của bộ từ điển các từ cảm xúc. Nhưng lại có ưu điểm là dễ thực hiện, chi phí tính toán nhanh, chỉ mất công sức trong việc xây dựng bộ từ điển các từ cảm xúc mà thôi.
Phương pháp Deep Learning Neural Network. Những thập niên gần đây, với sự phát triển nhanh chóng tốc độ xử lý của CPU, GPU và chi phí cho phần cứng ngày càng giảm, các dịch vụ hạ tầng điện toán đám mây ngày càng phát triển, làm tiền đề và cơ hội cho phương pháp học sâu Deep Learning Neural Network phát triển mạnh mẽ. Trong đó, bài toán phân tích cảm xúc đã được giải quyết bằng mô hình học Recurrent Neural Network (RNN) với một biến thể được dùng phổ biến hiện nay là Long Short Term Memory Neural Network (LSTMs), kết hợp với mô hình vector hóa từ (vector representations of words) Word2Vector với kiến trúc Continuous Bag-of-Words (CBOW). Mô hình này cho độ chính xác hơn 85%. Ưu điểm của phương pháp này là văn bản đầu vào có thể là 1 câu hay 1 đoạn văn. Để thực hiện mô hình này đòi hỏi phải có dữ liệu văn bản càng nhiều càng tốt để tạo Word2Vector CBOW chất lượng cao và dữ liệu gán nhãn lớn để huấn luyện (training), xác minh (validate) và kiểm tra (test) mô hình học có giám sát (Supervise Learning) LSTMs.
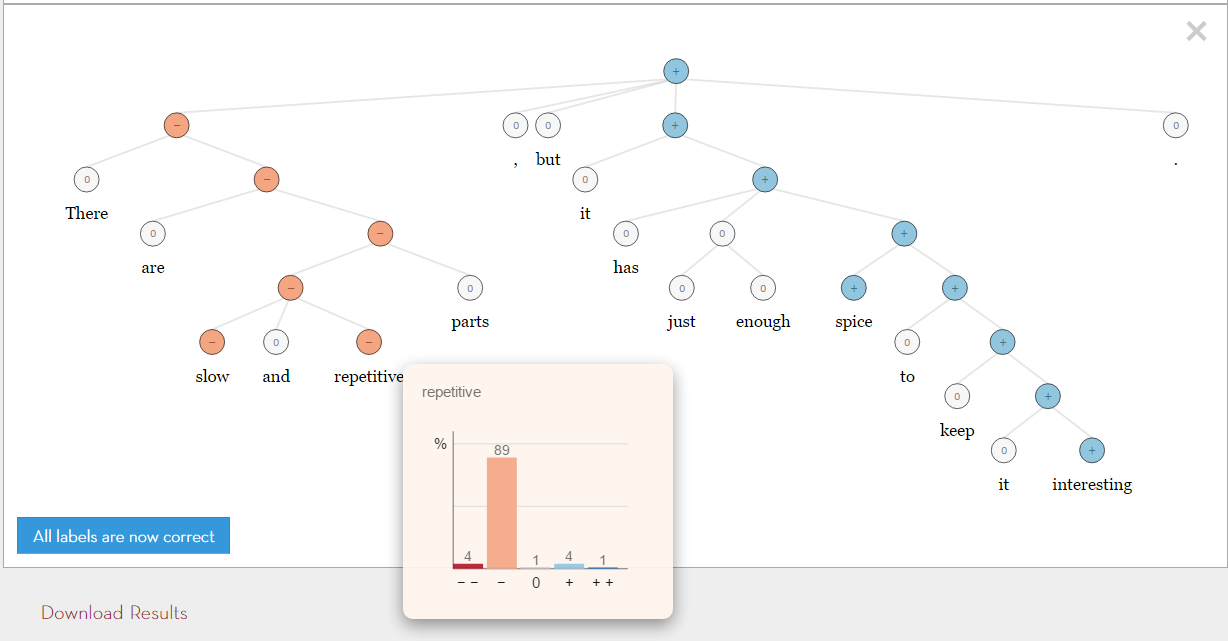
Phương pháp kết hợp Rule-bases (dựa trên luật) và Corpus-bases (dựa trên ngữ liệu). Tiêu biểu cho phương pháp này là công trình nghiên cứu của Richard Socher thuộc trường đại học Stanford. Các bạn có thể tham khảo thêm ở đây: http://nlp.stanford.edu/sentiment/. Phương pháp này kết hợp sử dụng mô hình Deep Learning Recursive Neural Network với hệ tri thức chuyên gia trong xử lý ngôn ngữ tự nhiên (XLNNTN) được gọi là Sentiment Treebank. Sentiment Tree là cây phân tích cú pháp của 1 câu văn, trong đó mỗi nút trong cây kèm theo bộ trọng số cảm xúc lần lượt là: rất tiêu cực (very negative), tiêu cực (negative), trung tính (neutral), tích cực (positive) và rất tích cực (very positive). Theo đó, trọng số thuộc nhãn nào lớn nhất sẽ quyết định nhãn toàn cục của nút, như hình dưới đây. Độ chính xác của mô hình khi dự đoán cảm xúc cho 1 câu đơn là 85,4%. Nhược điểm của phương pháp này ở chổ chỉ xử lý tốt cho dữ liệu đầu vào là một câu đơn.
Dựa trên các phân tích trên, chúng tôi quyết định chọn phương pháp deep learning LSTMs kết hợp với Word2Vector để giải quyết bài toán phân tích cảm xúc. Mô hình này tỏ ra sát với yêu cầu ứng dụng thực tiễn với văn bản đầu vào là một đoạn văn bất kỳ, có thể là các bình luận (comment) trên mạng xã hội, các đánh giá (review) trên các trang web bán hàng, cung cấp dịch vụ ăn uống, giải trí, du lịch như: các quán ăn, nhà hàng, khách sạn, địa điểm du lịch, rạp chiếu phim, bộ phim, các thương hiệu nổi tiếng... Đầu ra là phân lớp cảm xúc thành 2 loại: tiêu cực (negative) và tích cực (positive).
4. Sơ đồ huấn luyện mô hình phân tích cảm xúc văn bản Tiếng Việt (Sentiment Analysis Vietnamese - SAV).
Sơ đồ huấn luyện (training):
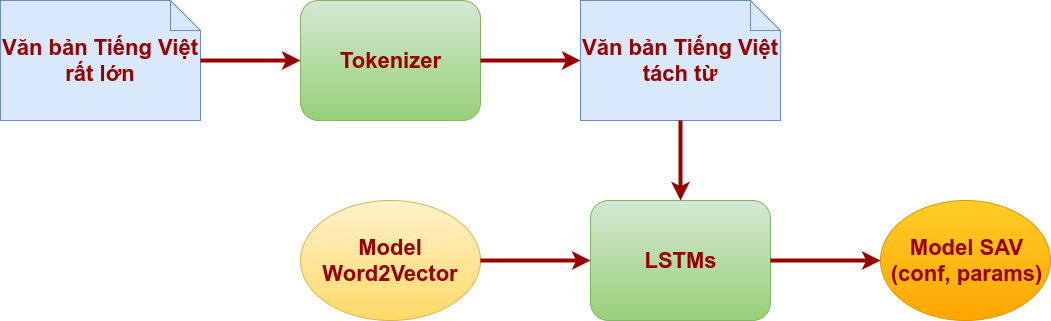
Theo như hình trên, thì ta thấy đầu vào của mô hình học có giám sát LSTMs là các tập tin đã gán nhãn, chứa các đoạn văn được xử lý tách từ (phân đoạn từ) bằng công cụ Tokenizer và mô hình Word2Vector.
Tiếng Việt thuộc loại hình đơn lập, ranh giới từ không được xác định mặc nhiên bằng khoản trắng, mà việc giải quyết bài toán lại liên quan đến ngữ nghĩa của từ cho nên việc phân đoạn từ là công việc bắt buộc để mô hình đạt được độ chính xác cao hơn, các bạn có thể đọc bài viết cách tách từ Tiếng Việt để hiểu thêm.
Còn mô hình Word2Vector là kết quả của quá trình huấn luyện nông dựa trên mô hình Recurrent Neural Network (RNN) để vector hóa từ, hay nói cách khác là đưa từ (word) vào không gian vector, các bạn có thể đọc bài viết cách tạo Word2Vector cho Tiếng Việt để hiểu thêm.
Kết quả của quá trình huấn luyện, ta thu được bộ trọng số của mạng nơ ron LSTMs được lưu xuống file (params) cùng với các siêu tham số cấu hình mạng LSTMs (conf) mà ta đã thiết lập. Hai tập tin này sẽ được tải vào (loading) vào mạng LSTMs để kiểm tra (test), vận hành (release) hoặc có thể tiếp tục huấn luyện (training) sau này.
Sơ đồ kiểm tra (test) và vận hành (release):
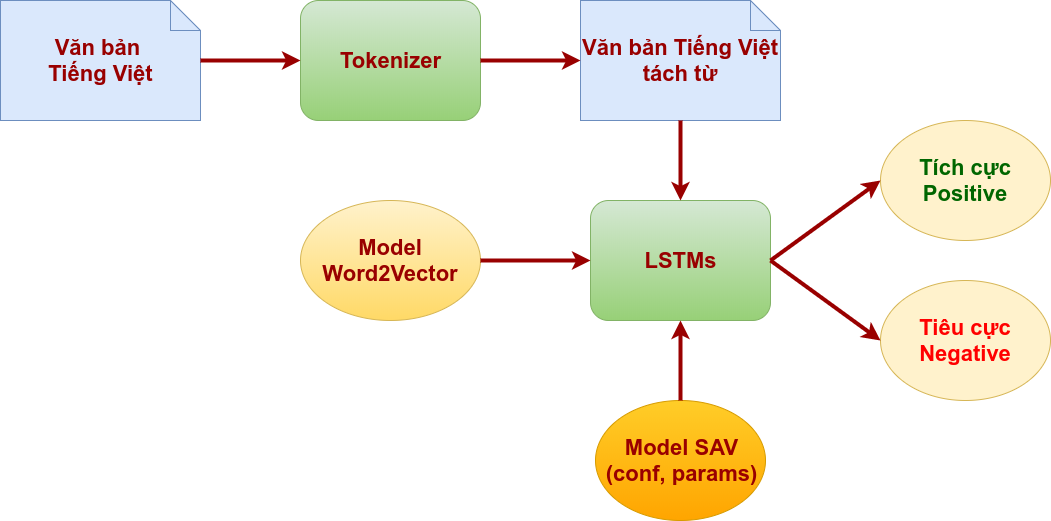
Ta thấy ở giai đoạn kiểm tra và vận hành này thì mô hình LSTMs tải lên các file cấu hình (conf) và file lưu bộ trọng số (params) của mạng nơ ron là kết quả của quá trình huấn luyện trước đó. Đồng thời vẫn phải sử dụng đến mô hình Word2Vector với vai trò là hệ tri thức từ vựng.
Quá trình kiểm tra, ta đưa vào bộ dữ liệu bao gồm các tập tin chứa các đoạn văn được gán nhãn đã tách từ bằng công cụ Tokenizer trước đó. Kết quả phân lớp đầu ra được ghi nhận lại để so sánh với nhãn mong đợi ban đầu của dữ liệu, qua đó cho ta kết quả độ chính xác của mô hình.
Nếu sau quá trình kiểm tra, độ chính xác của mô hình đạt được ở một mức độ chấp nhận được thì ta sử dụng kết quả mô hình này vào vận hành thực tế. Khi đưa mô hình vào vận hành thì dữ liệu đầu vào là chưa xác định nhãn và mục đích của mô hình phân tích cảm xúc được tạo ra là để gán nhãn dữ liệu đầu vào chưa gán nhãn này, phục vụ cho mục đích phân lớp dữ liệu. Kết quả dự đoán đầu ra được chấp nhận với một xác suất lỗi nhất định.
5. Một số lưu ý về điều chỉnh các siêu tham số của LSTMs.
Trong bài viết này, chúng tôi chưa vội phân tích nội hàm mạng nơ ron Long Short Term Memory Networks (LSTMs), nhằm để bài viết không quá dài, có thể chúng tôi sẽ trình bày mạng nơ ron LSTMs trong một bài viết khác vậy. Thay vào đó, chúng ta đi nhanh vào cách sử dụng mạng LSTMs sao cho hiệu quả, cụ thể trong trường hợp này là để giải quyết bài phân tích cảm xúc văn bản.
Trong lĩnh vực Deep Learning nói chung và mạng LSTMs nói riêng thì việc điều chỉnh các siêu tham số đầu vào khi khởi tạo một mô hình mạng, khá là khó khăn đối với cả những người đã có kinh nghiệm lâu năm, chứ đừng nói là người mới học hay mới tập tành tìm hiểu về Deep Learning. Tùy theo từng mô hình mạng phức tạp hay đơn giản mà số lượng siêu tham số cũng sẽ nhiều hay ít tương ứng.
Nói 1 cách dễ hiểu, ta tưởng tưởng việc điều chỉnh các siêu tham số của mạng deep learning giống như ta hiệu chỉnh âm thanh máy âm ly của giàn karaoke, với hơn 20 núm vặn và các nút bấm khác nhau. Người chưa có kinh nghiệp phải thử sai khá nhiều lần mới có được âm thanh ưng ý, trong khi người dùng có kinh nghiệm lâu năm thì chỉ cần 3-4 lần thử là đã thành công.
Có một điều cần lưu tâm là chi phí thời gian cho việc thử rồi biết mình sai khi huấn luyện mạng deep learning được tính bằng giờ, bằng ngày, ví dụ như thời gian training cho mô hình SAV trong bài viết này tốn hết 10h20’, cho nên việc hạn chế số lần thử sai có ý nghĩ hết sức to lớn cả về thời gian lẫn công sức bỏ ra.
Ở các phòng thí nghiệm lớn, người ta có thể giảm chi phí thời gian huấn luyện bằng cách dùng nhiều máy hơn để xử lý song song, vừa sử dụng GPU để tăng sức mạnh xử lý, nhưng đòi hỏi phải có tiền đầu tư hạ tầng lớn. Chính vì thế mà chúng tôi cố gắng viết thêm phần này để nêu lên một số kinh nghiệm thực hành mà các nhà khoa học đã tổng kết lại nhằm hạn chế vấn đề thử sai xuống mức thấp nhất có thể. Mà khi các bạn bắt tay vào thí nghiệm thì mới thấy thấm thía điều này.
Để bài viết được ngắn gọn thì chúng tôi chỉ xin trình bày những điều lưu ý khi điều chỉnh siêu tham số chỉ cho mạng LSTMs. Khi các bạn có nhiều trãi nghiệm hơn thì tự nhiên thấy việc điều chỉnh này cũng bình thường, vấn đề là bạn phải hiểu được ý nghĩa của từng tham số đóng vai trò như thế nào trong mạng deep learning mà mình sử dụng (cái này khó đó).
- Đầu tiên là Regularization methods, tạm dịch là phương pháp tinh chỉnh hay hiệu chỉnh mô hình học, nhằm giải quyết vấn đề quá khớp (Overfitting). Với mạng LSTMs các nhà khoa học khuyến cáo dùng 2 phương pháp có tên là L1 và L2, trong mô hình SAV chúng tôi chọn dùng L2.
- Tập dữ liệu test độc lập với tập dữ liệu train. Để đánh giá khách quan hơn về độ chính xác của mô hình.
-
Độ lớn của Network càng lớn thì càng mạnh mẽ, nhưng cũng dễ bị overfit. Đừng bao giờ cố gắng huấn luyện
mô hình có một triệu tham số (trọng số) chỉ với 10.000 mẫu dữ liệu. Chúng ta cần lưu ý đến quy tắc:
parameters > example = trouble
Tức là khi số lượng tham số lớn hơn số lượng mẫu thì ta sẽ gặp vấn đề quá khớp (Overfitting). - Nhiều dữ liệu huấn luyện hơn thì hầu như luôn tốt hơn, chống lại hiện tượng quá khớp (overfitting) như quy tắc ở trên.
- Huấn luyện lại nhiều lần (epochs). Cùng một tập dữ liệu huấn luyện xác định, thì mô hình sẽ được học lại nhiều lần dữ liệu đó để cải thiện độ chính xác của mô hình qua từng lần học. Thông thường siêu tham số epochs này nằm trong khoảng từ 1-5 lần. Đương nhiên về mặt lý thuyết, epochs càng cao thì càng tốt nhưng đổi lại là chi phí thời gian huấn luyện càng lâu. Kiểu như "nhai kỹ no lâu, cày sâu tốt lúa" vậy. Mô hình sẽ học nhiều hơn từ dữ liệu nếu được huấn luyện nhiều lần hơn.
-
Luôn có tập evaluate để đánh giá qua mỗi epoch để biết khi nào thì cần kết thúc (có thể kết thúc sớm).
Trong quá trình huấn luyện khi kết thúc 1 lượt học dữ liệu training của mô hình (epoch), ta nên có tập evaluate để đánh giá độ chính xác của mô hình qua từng lần học (epoch). Nếu quan sát thấy độ chính xác tăng dần qua mỗi lần học thì ta yên tâm rằng mô hình không bị quá khớp (Overfitting). Ngược lại, khi đến lần học thứ (n+1) ta thấy độ chính xác mô hình bị tụt giảm so với lần n trước đó và tiếp tục tụt giảm ở lần học thứ (n+2) thì ta nên kết thúc sớm quá trình học để tinh chỉnh lại các siêu tham số, rồi huấn luyện lại, tránh lãng phí thời gian vô ích.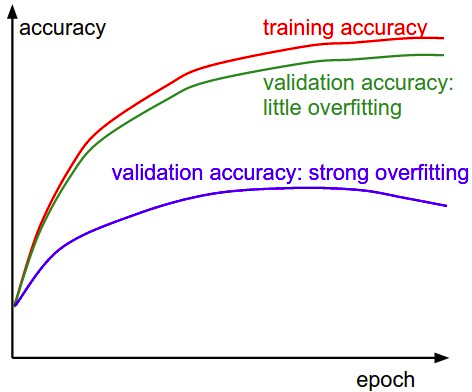
-
Tỷ lệ học (learning rate) là 1 tham số rất quan trọng. Nó ảnh hưởng đến độ lỗi của mô hình trong
suốt quá trình học.
Như hình trên cho chúng ta thấy 4 trường hợp có thể xảy ra khi thiết lập giá trị learning rate trong quá trình huấn luyện mô hình. Nhìn vào hình dạng của đồ thị độ lỗi của mô hình qua các lần học ta có thể nhận ra việc chúng ta thiết lập tỷ lệ học ban đầu là thấp, cao hay quá cao so với giá trị tốt nhất, nhằm kịp thời dừng việc huấn luyện lại để điều chỉnh lại tỷ lệ học.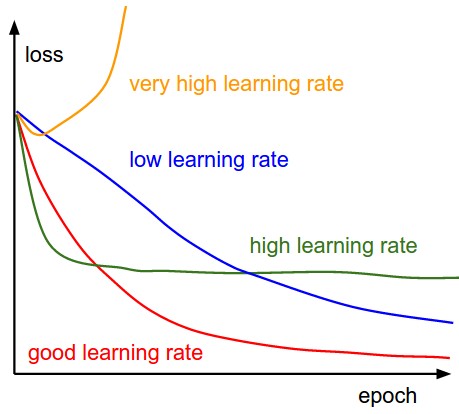
-
Với LSTMs, sử dụng softsign activation function (not softmax). Nhanh hơn và ít bị bão hòa hơn (~0 gradients).
\begin{equation*} f( x) \ =\ \frac{x}{1\ +\ | x| } \ \in ( -1,\ 1) \end{equation*}
- Updaters: RMSProp, AdaGrad hoặc Momentum (Nesterovs) là các thuật toán dùng để tối ưu siêu tham số tỷ lệ học trong suốt quá trình huấn luyện. Ba loại thuật toán này là những lựa chọn tốt cho mạng LSTMs so với các thuật toán khác. Với mô hình SAV thì Updater được chọn là RMSProp.
- Khởi tạo tham số (trọng số) với Xavier.
- Chuẩn hóa dữ liệu (data normalization) với việc sử dụng hàm lỗi MCXENT (MCXENT loss function) và softmax activation function cho quá trình tính toán hồi quy (regression). Ở đây, softmax được dùng để tính toán hồi quy ở đầu ra phân lớp của toàn hệ thống, đừng nhầm lẫn với softsign activation function nằm bên trong mạng LSTMs ở mục 8 ở trên.
Trên đây là một số điều lưu ý khi sử dụng mạng LSTMs, trong đó có các gợi ý cụ thể trong việc giải quyết bài toán phân tích cảm xúc trong Tiếng Việt (Sentiment Analysis Vietnamese - SAV). Sau đây là mô tả chi tiết hơn về cách dùng LSTMs trong thực nghiệm mô hình SAV.
6. Thực hành tạo mô hình Sentiment Analysis Vietnamese (SAV).
Sentiment Analysis Vietnamese (SAV) sử dụng mô hình GravesLSTM trong luận văn tiến sĩ của Graves, các bạn có thể tham khảo theo link sau: http://www.cs.toronto.edu/~graves/phd.pdf. Được thực thi bằng ngôn ngữ Java trong thư viện mã nguồn mở deeplearning4j phiên bản deeplearning4j 0.4-rc3.8. Chúng tôi chọn deeplearning4j viết bằng Java một phần là vì dễ tích hợp phần demo trên website StreetcodeVN này, các bạn có thể sử dụng mạng LSTMs trong các thư viện khác.
Sơ đồ kiến trúc mô hình mạng LSTMs như sau:
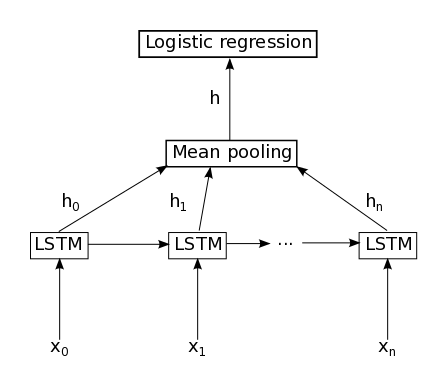
Số lượng nút LSTMs được dùng là 300 nút, hay n = 299. Vậy tương ứng với đầu vào của mô hình SAV là 300 từ Tiếng Việt. Đầu ra của mạng LSTMs là 300 vector ẩn từ h0 đến h299, được cho qua xử lý "mean pooling" để thu được một vector h có số chiều là 200 chiều. Sau cùng, vector h này được tính toán logic hồi quy để phân lớp, cho ra kết quả dự đoán nhãn cảm xúc cho đoạn văn đầu vào ban đầu là tiêu cực (negative) hay tích cực (positive).
Cụ thể hơn về việc cấu hình mạng LSMTs bằng thư viện deeplearning4j như sau:
//Set up network configuration deeplearning4j
int vectorSize = 300;
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
.iterations(1)
.updater(Updater.RMSPROP)
.regularization(true).l2(1e-5)
.weightInit(WeightInit.XAVIER)
.gradientNormalization(GradientNormalization.ClipElementWiseAbsoluteValue)
.gradientNormalizationThreshold(1.0)
.learningRate(0.0018)
.list(2)
.layer(0, new GravesLSTM.Builder().nIn(vectorSize).nOut(200)
.activation("softsign").build())
.layer(1, new RnnOutputLayer.Builder().activation("softmax")
.lossFunction(LossFunctions.LossFunction.MCXENT).nIn(200).nOut(2).build())
.pretrain(false).backprop(true).build();
Tóm lại, mô hình SAV chỉ tóm lại có bấy nhiêu dòng code thôi đó. Quan sát các thông số cấu hình của các dòng code trên, ta sẽ thấy tất cả các siêu tham số của mạng LSTMs mà chúng tôi đã đề cập trước đó, cụ thể như sau:
- Số chiều vector là 300, chính là số chiều vector của mỗi từ trong Word2Vector VNW2V.
- Regularization methods là L2.
- LSTMs sử dụng softsign activation function.
- Tỷ lệ học (learning rate) là 0.0018.
- Updater tối ưu siêu tham số tỷ lệ học là RMSProp.
- Khởi tạo tham số (trọng số) cho mạng LSTMs là Xavier.
- Softmax activation function và hàm lỗi MCXENT được sử dụng trong quá trình phân tích logic hồi quy.
Source code đầy đủ. Class MainApp:
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.URL;
import java.nio.file.Files;
import java.nio.file.Paths;
import org.apache.commons.compress.archivers.tar.TarArchiveEntry;
import org.apache.commons.compress.archivers.tar.TarArchiveInputStream;
import org.apache.commons.compress.compressors.gzip.GzipCompressorInputStream;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.FilenameUtils;
import org.deeplearning4j.datasets.iterator.AsyncDataSetIterator;
import org.deeplearning4j.datasets.iterator.DataSetIterator;
import org.deeplearning4j.earlystopping.saver.LocalFileModelSaver;
import org.deeplearning4j.eval.Evaluation;
import org.deeplearning4j.models.embeddings.loader.WordVectorSerializer;
import org.deeplearning4j.models.embeddings.wordvectors.WordVectors;
import org.deeplearning4j.nn.api.OptimizationAlgorithm;
import org.deeplearning4j.nn.conf.GradientNormalization;
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.Updater;
import org.deeplearning4j.nn.conf.layers.GravesLSTM;
import org.deeplearning4j.nn.conf.layers.RnnOutputLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.nn.weights.WeightInit;
import org.deeplearning4j.optimize.listeners.ScoreIterationListener;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.lossfunctions.LossFunctions;
/**
*
* @author nghiatc
* @since Mar 31, 2016
*/
public class MainApp {
/**
* Location to save and extract the training/testing data
*/
public static final String DATA_PATH = "/path/to/data/train/";
/**
* Location (local file system) for the model word2vector. Set this manually.
*/
public static final String WORD_VECTORS_PATH = "/path/to/data/vnw2v.bin";
// Directory save checkpoint MultiLayerNetwork.
public static final String CHECKPOINT_PATH = "/path/to/checkpoint/";
public static void main(String[] args) throws Exception {
long start = System.currentTimeMillis();
int batchSize = 50; //Number of examples in each minibatch
int vectorSize = 300; //Size of the word vectors. 300 in the model.
int nEpochs = 5; //Number of epochs (full passes of training data) to train on
int truncateReviewsToLength = 300; //Truncate reviews with length (# words) greater than this
//Set up network configuration
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT).iterations(1)
.updater(Updater.RMSPROP)
.regularization(true).l2(1e-5)
.weightInit(WeightInit.XAVIER)
.gradientNormalization(GradientNormalization.ClipElementWiseAbsoluteValue).gradientNormalizationThreshold(1.0)
.learningRate(0.0018)
.list(2)
.layer(0, new GravesLSTM.Builder().nIn(vectorSize).nOut(200)
.activation("softsign").build())
.layer(1, new RnnOutputLayer.Builder().activation("softmax")
.lossFunction(LossFunctions.LossFunction.MCXENT).nIn(200).nOut(2).build())
.pretrain(false).backprop(true).build();
ScoreIterationListener listener = new ScoreIterationListener(1);
MultiLayerNetwork net = new MultiLayerNetwork(conf);
net.init();
net.setListeners(listener);
//DataSetIterators for training and testing respectively
//Using AsyncDataSetIterator to do data loading in a separate thread; this may improve performance vs. waiting for data to load
WordVectors wordVectors = WordVectorSerializer.loadGoogleModel(new File(WORD_VECTORS_PATH), true, false);
DataSetIterator train = new AsyncDataSetIterator(new SentimentExampleIterator(DATA_PATH,wordVectors,batchSize,truncateReviewsToLength,true),1);
DataSetIterator test = new AsyncDataSetIterator(new SentimentExampleIterator(DATA_PATH,wordVectors,100,truncateReviewsToLength,false),1);
System.out.println("Starting training...");
for( int i=0; i < nEpochs; i++ ){
net.fit(train);
train.reset();
System.out.println("Epoch " + i + " complete. Starting evaluation:");
//Run evaluation. This is on 25k reviews, so can take some time
Evaluation evaluation = new Evaluation();
while(test.hasNext()){
DataSet t = test.next();
INDArray features = t.getFeatureMatrix();
INDArray lables = t.getLabels();
INDArray inMask = t.getFeaturesMaskArray();
INDArray outMask = t.getLabelsMaskArray();
INDArray predicted = net.output(features,false,inMask,outMask);
evaluation.evalTimeSeries(lables,predicted,outMask);
}
test.reset();
System.out.println(evaluation.stats());
System.out.println("Save checkpoint MultiLayerNetwork time " + i + "..............");
String confPath = CHECKPOINT_PATH + "conf" + i + ".json";
String netPath = CHECKPOINT_PATH + "sentimentNet" + i + ".bin";
try {
//Write the network configuration:
FileUtils.write(new File(confPath), net.getLayerWiseConfigurations().toJson());
System.out.println("Save file conf: " + confPath);
//Write the network parameters:
DataOutputStream dos = new DataOutputStream(Files.newOutputStream(Paths.get(netPath)));
Nd4j.write(net.params(), dos);
System.out.println("Save sentimentNet: " + netPath);
} catch (Exception e) {
}
}
//saveLatestModel
System.out.println("Save saveLatestModel...");
LocalFileModelSaver saver = new LocalFileModelSaver(CHECKPOINT_PATH);
saver.saveLatestModel(net, 1);
System.out.println("----- Example complete -----");
System.out.println("===== Example complete Time: " + (System.currentTimeMillis() - start) + " ms");
}
}
Các bạn lưu ý chỉnh sửa các biến DATA_PATH, WORD_VECTORS_PATH, CHECKPOINT_PATH theo đúng đường dẫn thư mục trong máy tính của mình.
Lớp tiện ích đọc dữ liệu train, validate và test. Class SentimentExampleIterator.
import java.io.File;
import java.io.IOException;
import java.util.*;
import java.util.NoSuchElementException;
import java.util.concurrent.ConcurrentHashMap;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.FilenameUtils;
import org.deeplearning4j.datasets.iterator.DataSetIterator;
import org.deeplearning4j.models.embeddings.wordvectors.WordVectors;
import org.deeplearning4j.text.tokenization.tokenizer.preprocessor.CommonPreprocessor;
import org.deeplearning4j.text.tokenization.tokenizerfactory.DefaultTokenizerFactory;
import org.deeplearning4j.text.tokenization.tokenizerfactory.TokenizerFactory;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.dataset.api.DataSetPreProcessor;
import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.indexing.INDArrayIndex;
import org.nd4j.linalg.indexing.NDArrayIndex;
/**
*
* @author nghiatc
* @since Mar 31, 2016
*/
public class SentimentExampleIterator implements DataSetIterator {
private final WordVectors wordVectors;
private final int batchSize;
private final int vectorSize;
private final int truncateLength;
private int cursor = 0;
private final File[] positiveFiles;
private final File[] negativeFiles;
private final TokenizerFactory tokenizerFactory;
private Map mapIndexRandom;
/**
* @param dataDirectory the directory of the data set
* @param wordVectors WordVectors object
* @param batchSize Size of each minibatch for training
* @param truncateLength If reviews exceed
* @param train If true: return the training data. If false: return the testing data.
*/
public SentimentExampleIterator(String dataDirectory, WordVectors wordVectors, int batchSize, int truncateLength, boolean train) throws IOException {
this.batchSize = batchSize;
this.vectorSize = wordVectors.lookupTable().layerSize();
File pos = new File(FilenameUtils.concat(dataDirectory, (train ? "train" : "test") + "/pos/") + "/");
File neg = new File(FilenameUtils.concat(dataDirectory, (train ? "train" : "test") + "/neg/") + "/");
positiveFiles = pos.listFiles();
negativeFiles = neg.listFiles();
this.wordVectors = wordVectors;
this.truncateLength = truncateLength;
tokenizerFactory = new DefaultTokenizerFactory();
tokenizerFactory.setTokenPreProcessor(new CommonPreprocessor());
int num = positiveFiles.length + negativeFiles.length;
mapIndexRandom = genRandomMapIndex(0, num);
}
@Override
public DataSet next(int num) {
if (cursor >= positiveFiles.length + negativeFiles.length) throw new NoSuchElementException();
try{
return nextDataSet(num);
}catch(IOException e){
throw new RuntimeException(e);
}
}
//0=pos, 1=neg.
private DataSet nextDataSet(int num) throws IOException {
//First: load reviews to String. Alternate positive and negative reviews
//Map mapIndexRandom = genRandomMapIndex(0, num);
List reviews = new ArrayList<>(num);
int[] positive = new int[num];
int segment1 = positiveFiles.length;
int segment2 = positiveFiles.length + negativeFiles.length;
for( int i=0; i < num && cursor < totalExamples(); i++ ){
int indexFile = mapIndexRandom.get(cursor);
if(0 <= indexFile && indexFile < segment1){
//Load positive review
int posReviewNumber = indexFile;
String review = FileUtils.readFileToString(positiveFiles[posReviewNumber]);
reviews.add(review);
positive[i] = 0;
} else if(segment1 <= indexFile && indexFile < segment2){
//Load negative review
int negReviewNumber = indexFile - segment1;
String review = FileUtils.readFileToString(negativeFiles[negReviewNumber]);
reviews.add(review);
positive[i] = 1;
}
cursor++;
}
//Second: tokenize reviews and filter out unknown words
List> allTokens = new ArrayList<>(reviews.size());
int maxLength = 0;
for(String s : reviews){
List tokens = tokenizerFactory.create(s).getTokens();
List tokensFiltered = new ArrayList<>();
for(String t : tokens ){
if(wordVectors.hasWord(t)) tokensFiltered.add(t);
}
allTokens.add(tokensFiltered);
maxLength = Math.max(maxLength,tokensFiltered.size());
}
//If longest review exceeds 'truncateLength': only take the first 'truncateLength' words
if(maxLength > truncateLength) maxLength = truncateLength;
//Create data for training
//Here: we have reviews.size() examples of varying lengths
INDArray features = Nd4j.create(reviews.size(), vectorSize, maxLength); // N:300:300
INDArray labels = Nd4j.create(reviews.size(), 2, maxLength); // N:2:300 //Two labels: positive or negative
//Because we are dealing with reviews of different lengths and only one output at the final time step: use padding arrays
//Mask arrays contain 1 if data is present at that time step for that example, or 0 if data is just padding
INDArray featuresMask = Nd4j.zeros(reviews.size(), maxLength); // N:300
INDArray labelsMask = Nd4j.zeros(reviews.size(), maxLength); // N:300
int[] temp = new int[2];
for( int i=0; i < reviews.size(); i++ ){
List tokens = allTokens.get(i);
temp[0] = i;
//Get word vectors for each word in review, and put them in the training data
for( int j=0; j < tokens.size() && j < maxLength; j++ ){
String token = tokens.get(j);
INDArray vector = wordVectors.getWordVectorMatrix(token);
features.put(new INDArrayIndex[]{NDArrayIndex.point(i), NDArrayIndex.all(), NDArrayIndex.point(j)}, vector);
temp[1] = j;
featuresMask.putScalar(temp, 1.0); //Word is present (not padding) for this example + time step -> 1.0 in features mask
}
int idx = positive[i]; //(positive[i] ? 0 : 1);
int lastIdx = Math.min(tokens.size(),maxLength);
labels.putScalar(new int[]{i,idx,lastIdx-1},1.0); //Set label:[1,0] for positive, [0,1] for negative
labelsMask.putScalar(new int[]{i,lastIdx-1},1.0); //Specify that an output exists at the final time step for this example
}
return new DataSet(features,labels,featuresMask,labelsMask);
}
public Map genRandomMapIndex(int min, int max){
Map mapIndex = new ConcurrentHashMap();
for(int i=0; i < max; i++){
mapIndex.put(i, i);
}
//System.out.println("In mapData: " + mapData);
for(int i=0; i < max + 1000; i++){
int a = randomRange(min, max);
int b = randomRange(min, max);
//swap value of 2 key.
mapIndex.put(a, mapIndex.put(b, mapIndex.get(a)));
}
//System.out.println("Out mapData: " + mapData);
return mapIndex;
}
public int randomRange(int min, int max){
Random r = new Random();
return r.nextInt(max - min) + min;
}
@Override
public int totalExamples() {
return positiveFiles.length + negativeFiles.length;
}
@Override
public int inputColumns() {
return vectorSize;
}
@Override
public int totalOutcomes() {
return 2;
}
@Override
public void reset() {
cursor = 0;
}
@Override
public int batch() {
return batchSize;
}
@Override
public int cursor() {
return cursor;
}
@Override
public int numExamples() {
return totalExamples();
}
@Override
public void setPreProcessor(DataSetPreProcessor preProcessor) {
throw new UnsupportedOperationException();
}
@Override
public List getLabels() {
return Arrays.asList("positive", "negative");
}
@Override
public boolean hasNext() {
return cursor < numExamples();
}
@Override
public DataSet next() {
return next(batchSize);
}
@Override
public void remove() {
}
/** Convenience method for loading review to String */
public String loadReviewToString(int index) throws IOException{
File f;
if(index%2 == 0) f = positiveFiles[index/2];
else f = negativeFiles[index/2];
return FileUtils.readFileToString(f);
}
/** Convenience method to get label for review */
public boolean isPositiveReview(int index){
return index%2 == 0;
}
}
Trong đó, cấu trúc thư mục data như sau:
.
├── test
│ ├── neg
│ │ ├── 1.txt
│ │ ├── 2.txt
│ │ ├── 3.txt
│ │ └── ...txt
│ └── pos
│ ├── 1.txt
│ ├── 2.txt
│ ├── 3.txt
│ └── ...txt
└── train
├── neg
│ ├── 1.txt
│ ├── 2.txt
│ ├── 3.txt
│ └── ...txt
└── pos
├── 1.txt
├── 2.txt
├── 3.txt
└── ...txt
Các hướng dẫn chi tiết hơn về việc sử dụng mạng LSTMs của thư viện deeplearning4j, các bạn có thể tham khảo ở bài hướng dẫn này.
Đến đây có lẽ là kết thúc phần trình bày về thực hành tạo mô hình Sentiment Analysis Vietnamese (SAV). Mong rằng qua bài viết này các bạn cũng có một số ý niệm về SAV, vấn đề cuối cùng là các bạn cần bỏ ra chút thời gian và công sức để có những trãi nghiệm thú vị của riêng mình mà thôi.
7. Phương pháp đánh giá mô hình Sentiment Analysis Vietnamese (SAV).
Cách đánh giá độ chính xác của mô hình SAV thông qua các độ đo Accuracy, Precision, Recall và F1 Score được tính bằng các công thức sau:
Với P là tổng số bình luận được gán nhãn là tích cực (Positive) và N là tổng số bình luận được gán nhãn là tiêu cực (Negative).
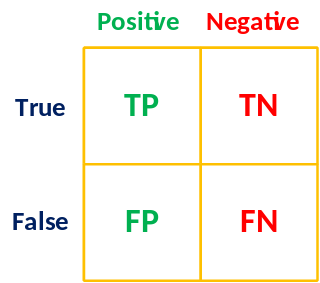
- P: Total Positive.
- N: Total Negative.
- Accuracy = (TP + TN) / (P + N)
- Precision = TP / (TP + FP)
- Recall = TP / (TP + FN)
- F1 Score = 2 * TP / (2TP + FP + FN)
Mô hình Sentiment Analysis Vietnamese (SAV)
Mô hình Sentiment Analysis Vietnamese (SAV) được huấn luyện, xác minh và kiểm tra với tập dữ liệu 50.000 mẫu dữ liệu bình luận (review) của người dùng, được gán nhãn là tích cực và tiêu cực dựa trên điểm số của đánh giá đó. Được phân chia như sau:
- Số lượng mẫu tập train là 30.000 bình luận.
- Số lượng mẫu tập validate là 10.000 bình luận.
- Số lượng mẫu tập test là 10.000 bình luận.
Các thí nghiệp được thực hiện trên phần cứng như sau:
- CPU: Intel core i7, 8 x 2.5GHz.
- RAM: 8GB.
- OS: Ubuntu 15.10 64bit.
Thời gian để huấn luyện mô hình SAV là 10h20'.
Kết quả kiểm tra là:
- Accuracy: 0.8764
- Percision: 0.8764
- Recall: 0.8764
- F1 Score: 0.8764
Đến đây thì bài viết cũng đã khá dài rồi.
Nếu có thắc mắc hoặc góp ý gì, các bạn có thể để lại bình luận ở bên dưới. Nếu bài viết này có ích cho bạn, thì bạn có thể like và share thoải mái.
Happy coding!!!
18h18PM, 14/02/2018

